Managing Files
My Files is the central file management area in the TRE platform. It is the place to upload input data before a pipeline run, access outputs after a pipeline run or workstation analysis completes, and review a log of file activity across the platform.
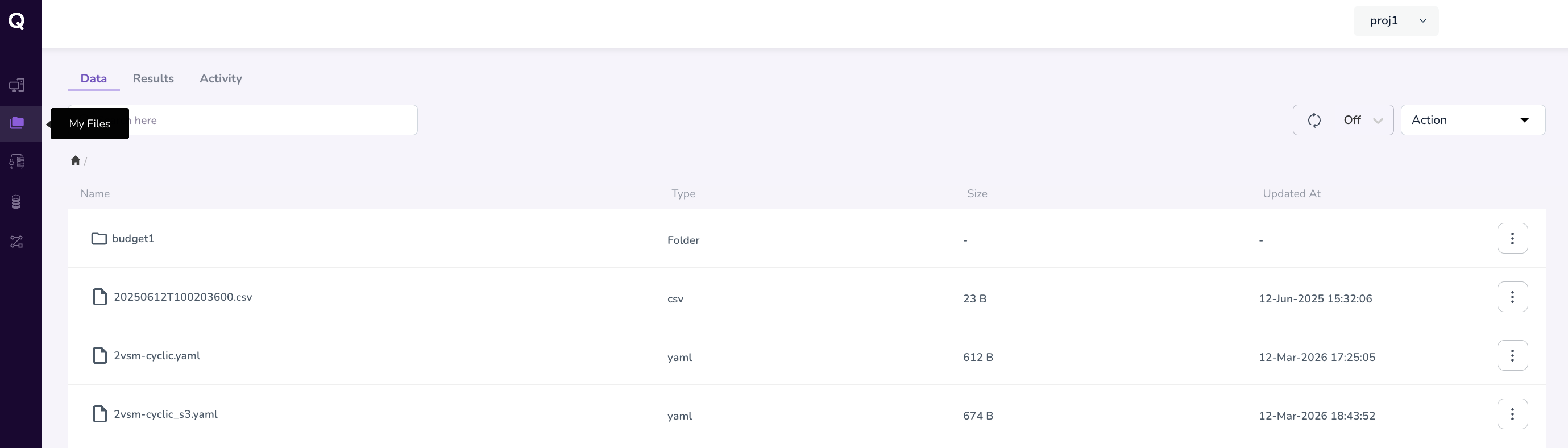
Overview of Tabs
My Files is organised into three tabs:
| Tab | Purpose |
|---|---|
| Data | Upload and manage input files for use in pipeline runs |
| Results | Access output files and artefacts from completed pipeline runs |
| Activity | View a log of file-level actions and changes |
Data Tab
The Data tab is where you store input files that pipelines or workstations can use as source data or input data. These might include files such as:
- Protein structure files (
.pdb) - Sequencing data (
.fastq,.fastq.gz) - Alignment files (
.bam,.sam) - Reference genomes or annotation files
Uploading Files
- Navigate to My Files from the left navigation pane
- Click the Data tab
-
Click the Action button, and from the drop-down, select between New Folder (to create folders for your different projects), Upload Data, Upload from Server and CLI Auth Token
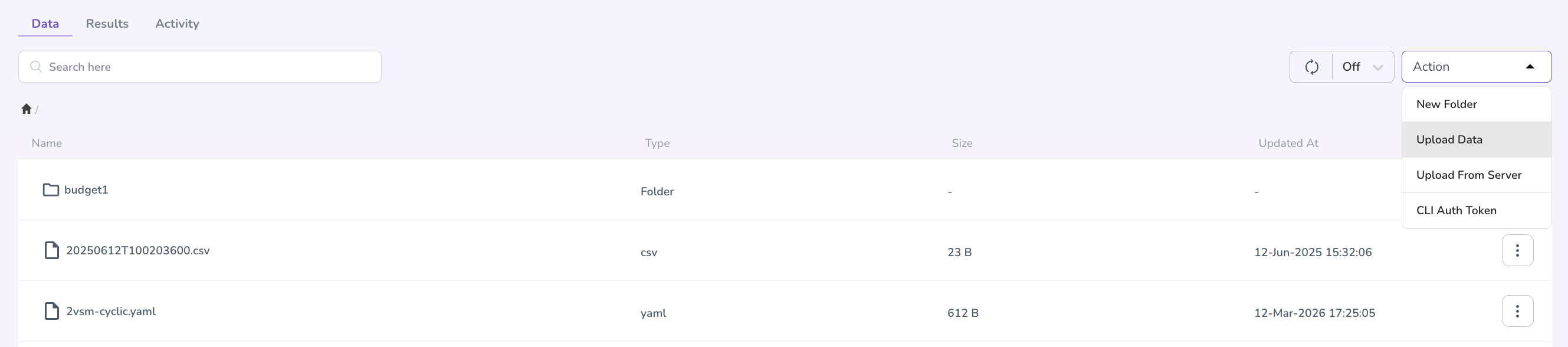
-
If you select Upload Data, select the file(s) you wish to upload from your local machine. Wait for the upload to complete — uploaded files will appear in the file list once approved by your project administrator
-
If you select Upload from Server, specify the Server Type (HTTP, SFTP, S3, SRA/ENA/DDBJ/GEO) and upload your data from the server location
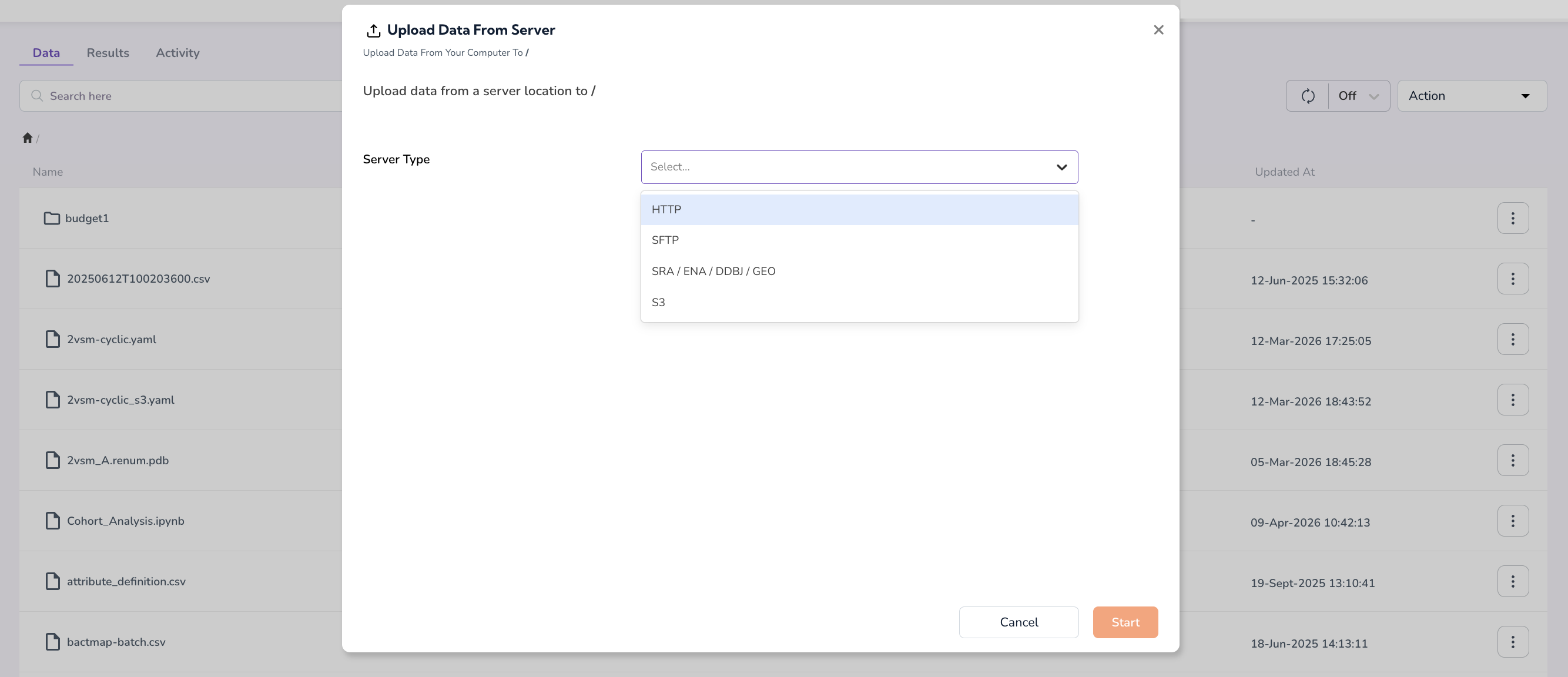
Important: For uploading and downloading large files or folders, refer to MyFiles CLI for a step-by-step guide on using the MyFiles CLI tool.
Tip: Upload your input files before configuring a pipeline run. When you reach the Inputs step during a run, you will be able to select files directly from My Files → Data. For example, When configuring pipeline inputs, file fields (e.g. the PDB file selector in the Boltzgen pipeline) will allow you to browse and select from files already uploaded to the Data tab. You do not need to re-upload files for each run — previously uploaded files remain available.
Results Tab
The Results tab stores all output files and artefacts generated by completed pipeline runs and workstation analyses. Results are organised by Jobs (pipeline runs) and Workstations, making it easy to locate outputs from a specific execution.
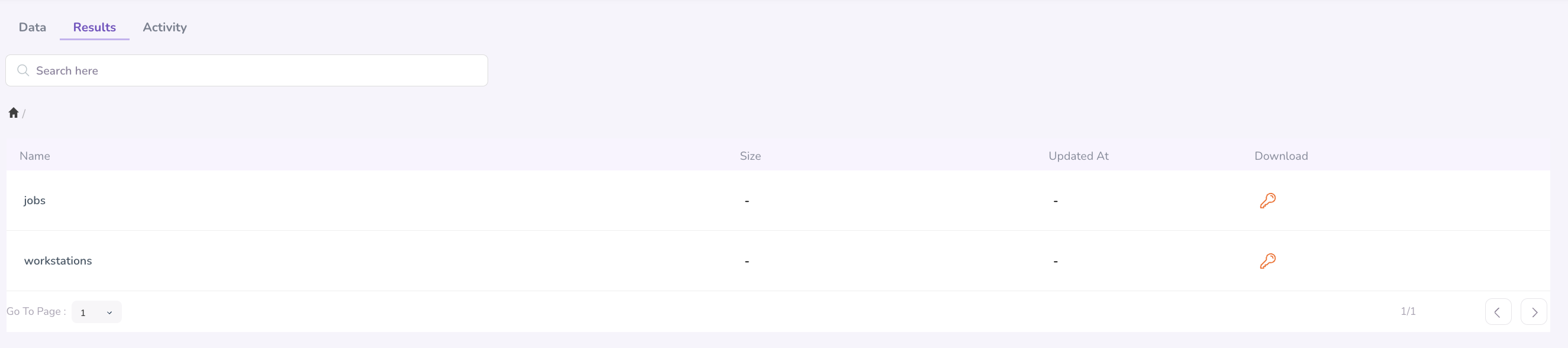
Accessing Results
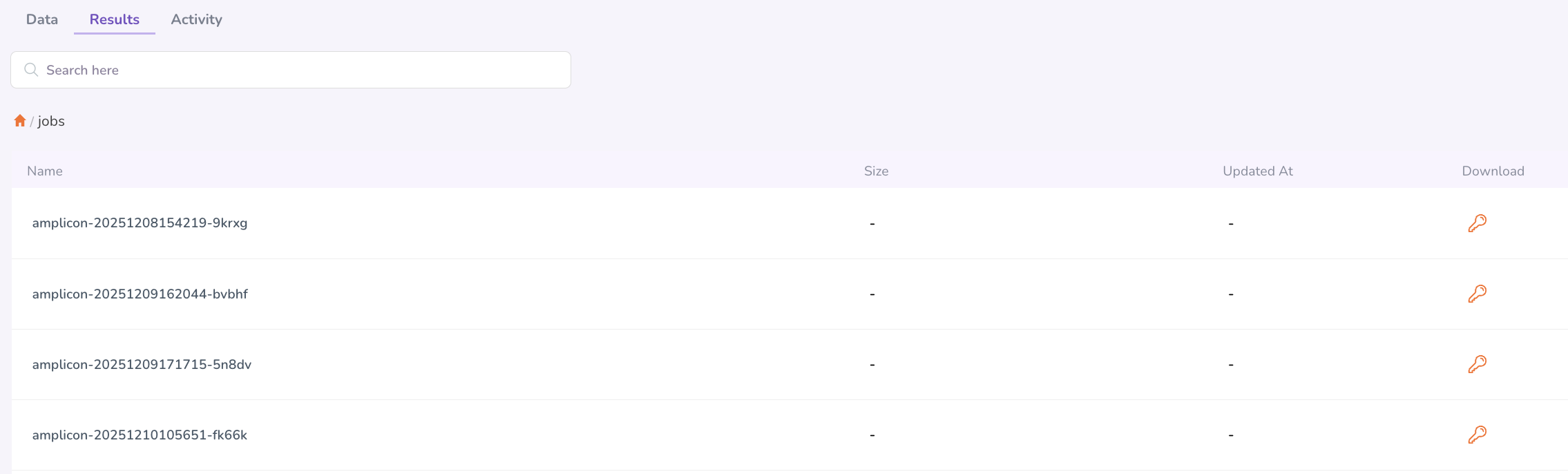
- Navigate to My Files → Results. If you're looking, for example, for a pipeline run, click Jobs
- Browse or search for the run whose outputs you need
- Click on a result entry to view or download the associated output files
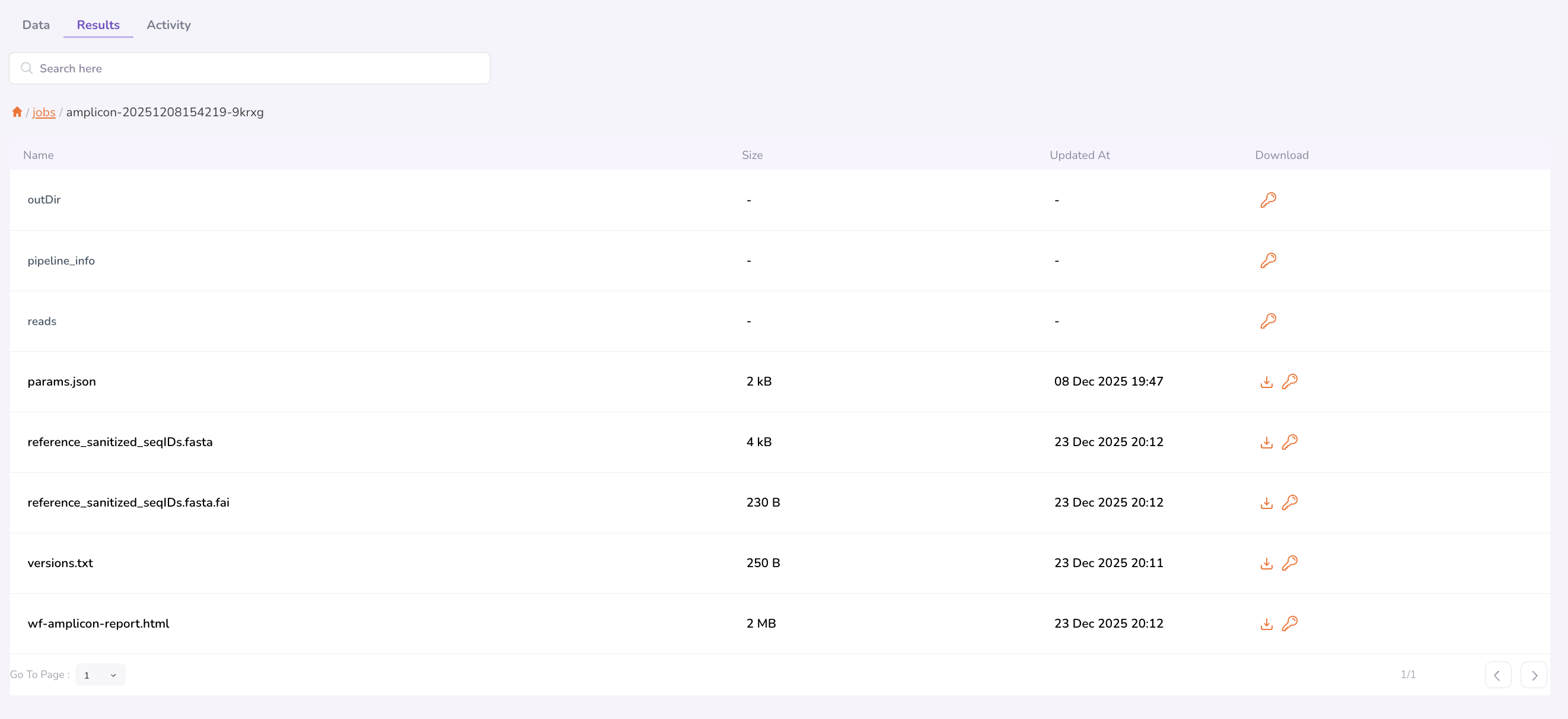
Clicking the download icon will trigger an approval workflow. You can track the status of your download request in My Requests. Once your request is approved by the TRE Administrator, you can navigate back to the same Results tab and folder to re-click the download icon. This will download your file to your local.
Important: For downloading large files or folders, refer to MyFiles CLI for a step-by-step guide on using the MyFiles CLIAuth tool.
What Results Are Generated?
The outputs available in the Results tab depend on the pipeline that was run. Examples include:
- Boltzgen — designed peptide sequences, structure prediction outputs
- DNA-Seq pipelines — variant call files (VCF), alignment summaries
Refer to the documentation for your specific pipeline to understand what outputs to expect and how to interpret them.
Activity Tab
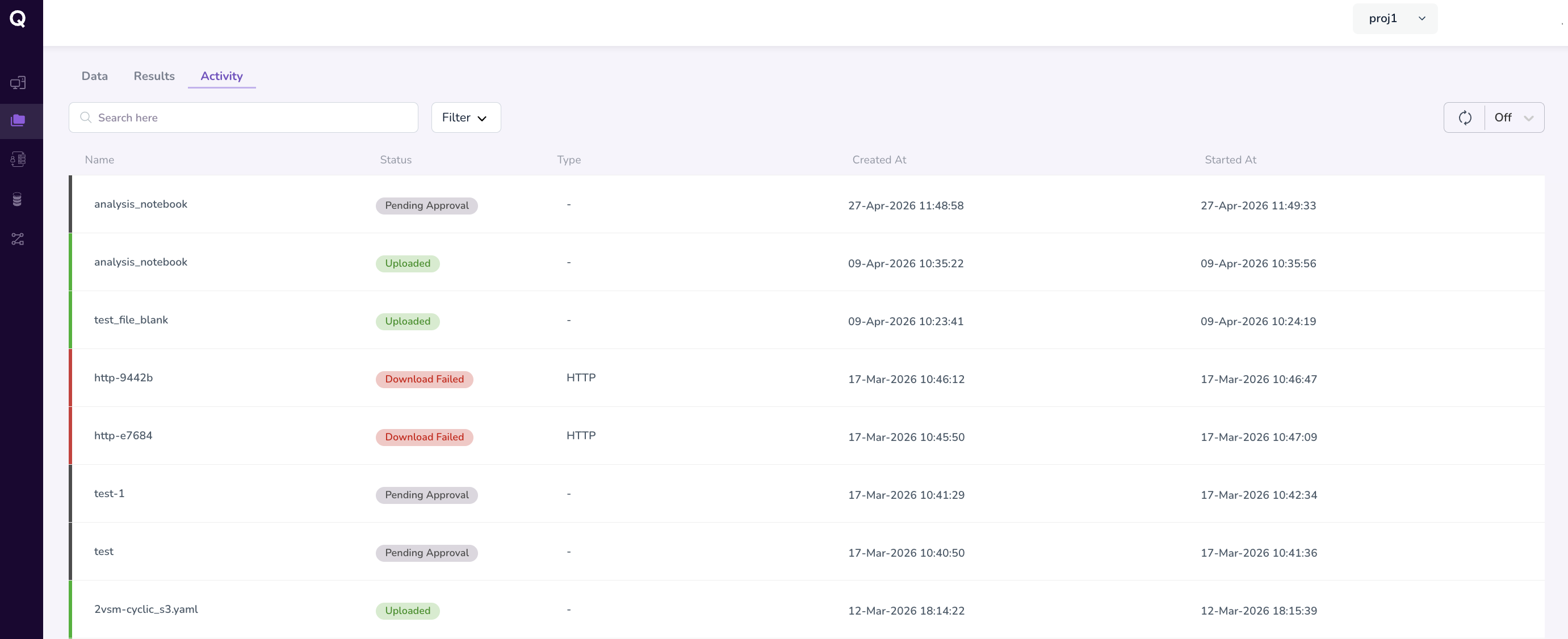
The Activity tab provides a chronological log of file-level actions taken within your My Files workspace. This includes events such as file uploads, deletions, and any other modifications.
Activity logs are useful for:
- Auditing which files were uploaded and when
- Tracking changes made to datasets over time
-
Troubleshooting issues related to missing or unexpected files
Tips and Best Practices
-
Name files clearly before uploading. Pipeline run history is easier to follow when input file names reflect the sample, date, or experiment (e.g.
sample01_R1.fastq.gzrather thanfile1.fastq.gz). -
Check the Data tab before starting a run or workstation analysis. All required
input files should be uploaded and visible in the Data tab before you begin configuring a pipeline run. -
Pipeline results are tied to runs. If you need to re-run a pipeline with different parameters, results from each run are stored separately and labelled by their run name — so use descriptive run names to keep things organised.
Further Reading
- Navigate to MyFiles CLI to learn how to transfer large files with the MyFiles CLI tool.